
- 下载云笔记到本地为MD文件。
现在的主流云笔记都是可以导出md格式的文件,blog备份 也是,我这里使用 有道云笔记本的开源下载工具 - 使用chromadb把MD文件 生成向量数据库。
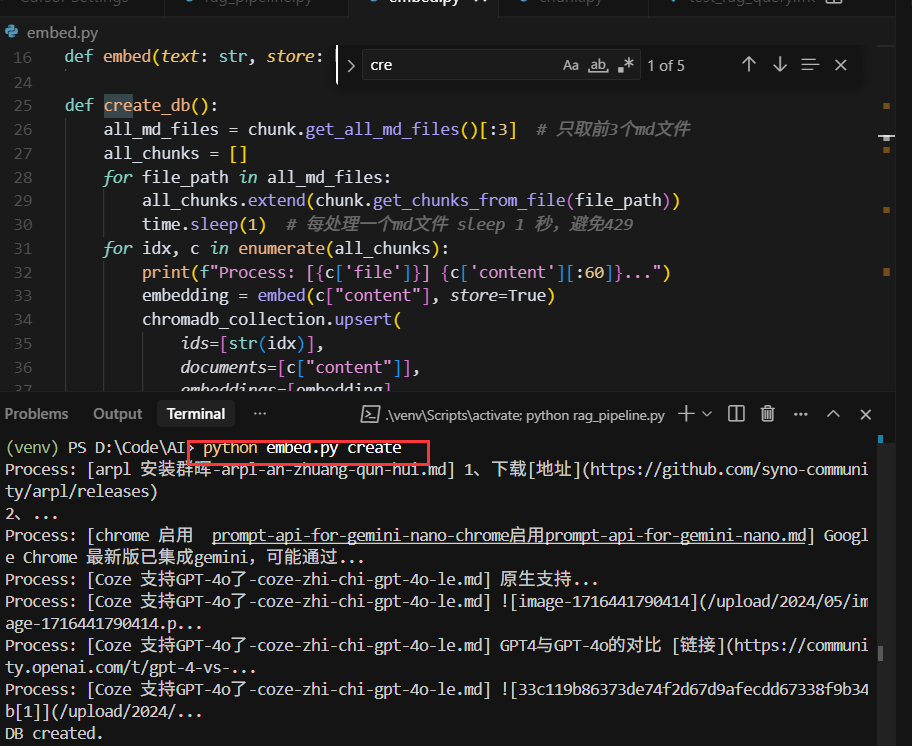
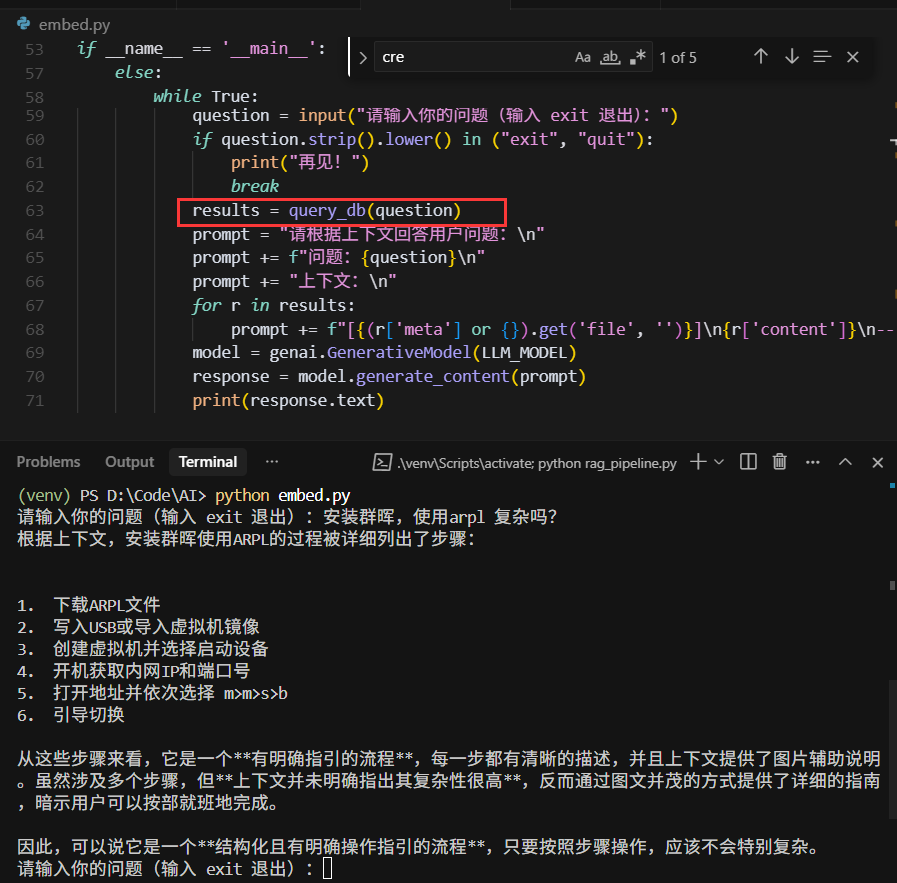
- 使用免费的gemini-embedding 模型,使用向量数据的内容回答问题。
-
现在做个人知识库基本上是0成本,只需要在google studio上申请一个API Key,几行代码就可以实现完整的问答系统。如果MD文件比较多时,注意调整调用API写入数据库的频率,不控制 十几次就报429错误,加上sleep(1)可解。
-
import google.generativeai as genai import time import chunk import chromadb EMBEDDING_MODEL = "gemini-embedding-exp-03-07" LLM_MODEL = "gemini-2.5-flash-preview-05-20" # 配置 API KEY API_KEY = "xxxxxxxx-xx-xxxx" genai.configure(api_key=API_KEY) chromadb_client = chromadb.PersistentClient("./chroma_gemini.db") chromadb_collection = chromadb_client.get_or_create_collection("linghuchong_gemini") def embed(text: str, store: bool) -> list[float]: response = genai.embed_content( model=EMBEDDING_MODEL, content=text, task_type="RETRIEVAL_DOCUMENT" if store else "RETRIEVAL_QUERY" ) assert response["embedding"] return response["embedding"] def create_db(): all_md_files = chunk.get_all_md_files()[:3] # 只取前3个md文件 all_chunks = [] for file_path in all_md_files: all_chunks.extend(chunk.get_chunks_from_file(file_path)) time.sleep(1) # 每处理一个md文件 sleep 1 秒,避免429 for idx, c in enumerate(all_chunks): print(f"Process: [{c['file']}] {c['content'][:60]}...") embedding = embed(c["content"], store=True) chromadb_collection.upsert( ids=[str(idx)], documents=[c["content"]], embeddings=[embedding], metadatas=[{"file": c["file"]}] ) print("DB created.") def query_db(question: str) -> list[dict]: question_embedding = embed(question, store=False) result = chromadb_collection.query( query_embeddings=[question_embedding], n_results=5 ) assert result["documents"] docs = result["documents"][0] metas = result.get("metadatas", [[]])[0] return [{"content": doc, "meta": meta} for doc, meta in zip(docs, metas)] if __name__ == '__main__': import sys if len(sys.argv) > 1 and sys.argv[1] == "create": create_db() else: while True: question = input("请输入你的问题(输入 exit 退出):") if question.strip().lower() in ("exit", "quit"): print("再见!") break results = query_db(question) prompt = "请根据上下文回答用户问题:\n" prompt += f"问题:{question}\n" prompt += "上下文:\n" for r in results: prompt += f"[{(r['meta'] or {}).get('file', '')}]\n{r['content']}\n-------------\n" model = genai.GenerativeModel(LLM_MODEL) response = model.generate_content(prompt) print(response.text) -
chunk.py ,如果是复杂的项目可以用 专业分词分词工具 langchain ,做chunk.
import os from typing import List, Dict def get_all_md_files(notes_dir: str = "data/notes") -> List[str]: return [ os.path.join(notes_dir, f) for f in os.listdir(notes_dir) if f.endswith('.md') ] def read_data(file_path: str) -> str: with open(file_path, "r", encoding="utf-8") as f: return f.read() def get_chunks_from_file(file_path: str) -> List[Dict]: content = read_data(file_path) chunks = content.split('\n\n') result = [] header = "" file_name = os.path.basename(file_path) for c in chunks: if c.strip().startswith("#"): header += f"{c.strip()}\n" else: if c.strip(): result.append({ "content": f"{header}{c.strip()}", "file": file_name }) header = "" return result def get_all_chunks(notes_dir: str = "data/notes") -> List[Dict]: all_chunks = [] for file_path in get_all_md_files(notes_dir): all_chunks.extend(get_chunks_from_file(file_path)) return all_chunks if __name__ == '__main__': for chunk in get_all_chunks(): print(f"[{chunk['file']}]\n{chunk['content']}\n--------------")