
在上一篇文章《从架构看极简:Lite Agent 如何用零外部依赖打造全功能 AI 助手引擎》中,我分享了如何坚持“0 外部依赖”的极客哲学,纯用 Python 标准库撸出一套具备多通道、长短期记忆和定时任务的智能助手。这套架构运行在廉价的云端 VPS 上,极其稳定。
但随着时间推移,我逐渐发现了一个痛点:它是个“盲人”。
每当我遇到需要解析的数学公式、拍下的纸质文档或是网页截图时,我只能手动把它们转成文字再发给它,十分割裂。于是,我萌生了一个念头——给这套极简系统装上“视觉神经”。
拒绝臃肿,寻找极致轻量的视觉方案
提到多模态 OCR,很多人第一时间想到的是接入商业 API,或是部署极其笨重的全家桶方案。但我的原则依然是:大道至简,拒绝臃肿。
经过一番调研,百度飞桨团队开源的 PaddleOCR-VL-1.5 进入了我的视线。
这是一个仅仅只有 0.9B 参数的超轻量级视觉-语言大模型(VLM),与目前百亿参数的模型相比,它小巧得不可思议,但在文档解析、复杂数学公式还原(OmniDocBench 测试)上却表现出了惊人的 94.5% 准确率。
更为关键的是,它可以被编译成 GGUF 格式!这意味着,我那台一直闲置在家里的 Mac Mini(M4 芯片) 终于有了用武之地。通过 llama.cpp,我可以直接利用 Apple Silicon 原生的 Metal 框架进行物理级 GPU 加速,没有任何厚重的 Python 依赖地狱。
极简部署:踩坑与极限优化的实战
原以为部署会一帆风顺,结果却结结实实踩了个坑。
一开始,我试图直接拉取原生 PyTorch 版本的底层环境来跑,结果直接遭遇了 Error loading model: 'default' 报错。更致命的是,在 Mac 的 M 系列芯片上,这套原生底层兼容性极差,纯 CPU 原生跑一页文档将近要 100 秒!
幸好后来查阅到了一篇“救星”文章,直接点破了迷局,并提供了一套专为 Apple Silicon 量身定制的最优解:“前端 paddleocr 客户端 + 底层 llama-server (GGUF格式模型)”。
于是我立刻转舵,采用了这套拥抱极速 GGUF 生态的架构方案:
-
底层推理引擎启动:放弃 PyTorch,直接掏出
llama.cpp编译出的llama-server,挂载视觉投影模块(mmproj)与量化好的 GGUF 模型,开启纯 C++ 的极致性能,并丢入后台永驻:# 1. 创建模型存放目录 mkdir -p ~/models/PaddleOCR-VL-1.5-GGUF cd ~/models/PaddleOCR-VL-1.5-GGUF # 2. 通过 hf-mirror 镜像源直链下载主模型 (约 900MB) curl -L -O -C - https://hf-mirror.com/PaddlePaddle/PaddleOCR-VL-1.5-GGUF/resolve/main/PaddleOCR-VL-1.5.gguf # 3. 下载视觉编码器 mmproj (约 840MB) curl -L -O -C - https://hf-mirror.com/PaddlePaddle/PaddleOCR-VL-1.5-GGUF/resolve/main/PaddleOCR-VL-1.5-mmproj.gguf #4. llama-server 启动 nohup llama-server -m ~/models/PaddleOCR-VL-1.5-GGUF/PaddleOCR-VL-1.5.gguf \ --mmproj ~/models/PaddleOCR-VL-1.5-GGUF/PaddleOCR-VL-1.5-mmproj.gguf \ --port 8080 --host 0.0.0.0 --temp 0 > ~/llama-server.log 2>&1 & -
前端客户端联动与 API 封装:安装好极其轻量的 paddleocr 客户端后,不再让它自己做重度推理,而是通过 --vl_rec_backend llama-cpp-server 参数,把最核心的识别任务外包给刚刚启动的 8080 端口。 由于最终需要给云端的 Agent 留接口,我又手撸了一个不到 100 行代码的 ocr_web.py(借助 FastAPI),在内部调用官方的 paddleocr doc_parser,向外暴露极简的 /api/ocr 接口。
-
极简 API 封装:由于底层只是纯粹的推理引擎,我又用不到 100 行代码手撸了一个
ocr_web.py。它利用 FastAPI 构建了一个超轻量的 Web 壳,并在内部调用官方的paddleocr doc_parser,最终向外暴露了一个极其干爽的/api/ocr接口。随后同样使用nohup挂在 8000 端口。
这套组合拳下来,原本 100 秒一页的龟速,被生生压缩到了不到 20 秒一页!一个全本地、不吃带宽的“视觉超算节点”就此在桌面上完美运转。
零入侵打通云端与本地:Tailscale 隧道
现在的局面是:
- 我的
Lite Agent运行在公网 VPS(云端) - 强大的视觉算力节点
Mac Mini运行在内网(本地)
如何将两者安全打通?我同样拒绝了复杂的 Nginx 反向代理或花生壳,而是选用了 Tailscale 虚拟局域网。
只要在家里启动服务,云端的 VPS 就能直接通过 100.x.x.x 的 Tailscale 私有 IP 连通家里的 API。没有任何公网暴露的风险,也没有复杂的鉴权,纯粹的点对点通信。
无感拦截:飞书与 Telegram 的“见图就解”
基础建好后,接下来就是改造 Lite Agent 的通道层。
我不想要什么花里胡哨的“图片上传指令”,最优雅的交互应当是隐形的。
在 channels/feishu.py 与 channels/telegram.py 中,我仅仅增加了几十行代码:监听消息池。如果发现是 image 或 photo 类型的消息,直接在后台新开一个轻量级 threading.Thread。
- 自动拦截: 无论是通过飞书还是 Telegram 发来的图片,机器人会立即回复一句:“🤔 收到图片,正在调用视觉大模型进行全版面结构化解析…”
- 下载透传: 服务端将原图抽离,通过 Socks5/官方 API 拉到内存,随后组装成极简的 HTTP POST 请求,通过 Tailscale 隧道射向我的卧室。
- 秒级直出: 家里的 Mac Mini 风扇微转,十几秒后,一篇包含完美 LaTeX 数学公式和排版还原的 Markdown 文本,直接呈现在我的手机屏幕上。
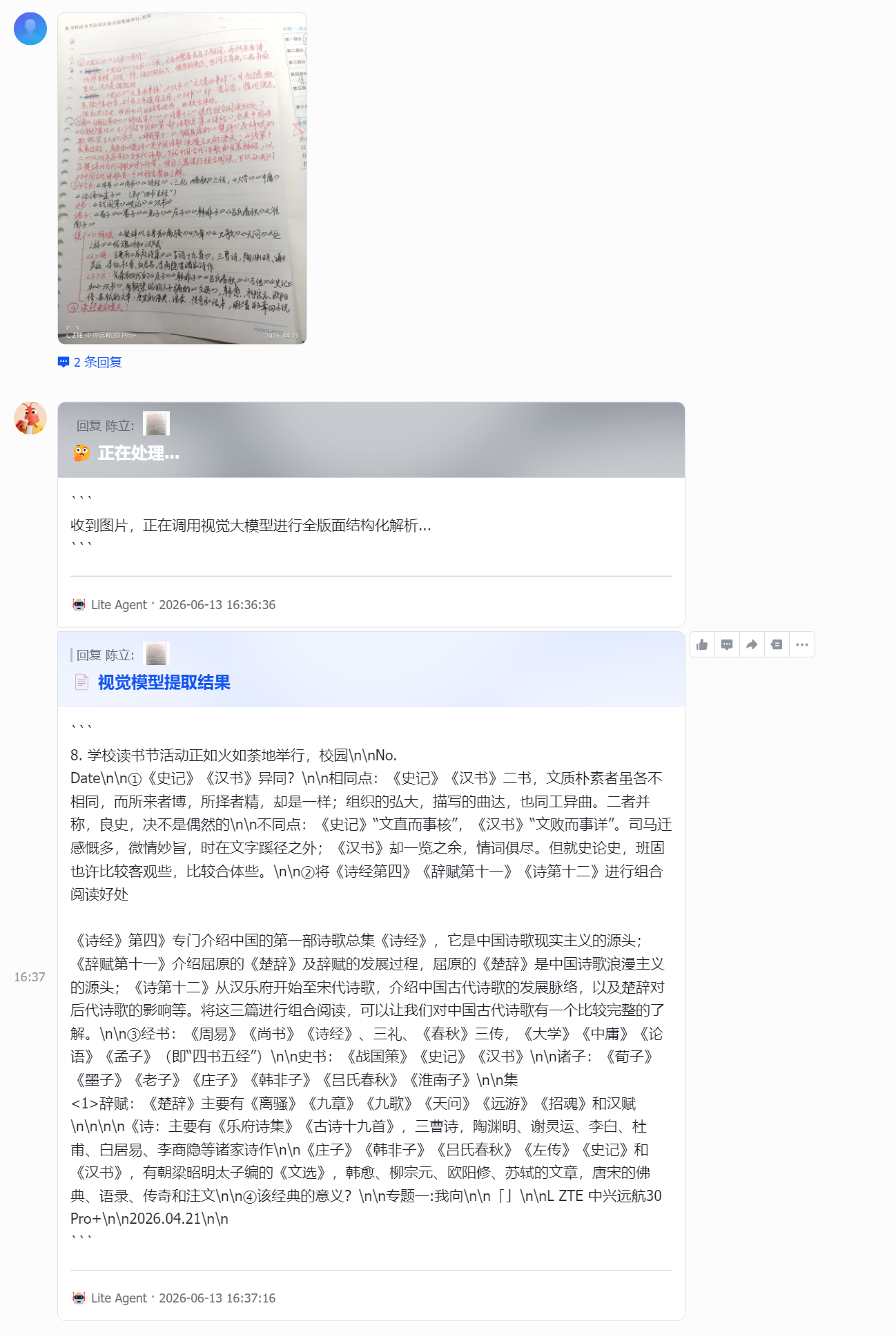
期间还遇到了一些小插曲。比如在 VPS 上添加.env环境变量OCR_ENDPOINT时,因为echo命令误把\n吃进去,导致系统读取了错乱的环境变量名,最后回退到了默认的本地127.0.0.1报错。不过这些都是折腾路上的小确幸。
结语
折腾到最后,看着手机屏幕里一张模糊的二次方程作业照,在几秒内变成了极其工整优雅的 LaTeX 代码输出时,那种成就感是难以言喻的。
在算力如此廉价、大模型百花齐放的今天,我们或许不需要用多高大上的企业级架构。只要找准工具的边界,用最简单直接的代码将它们串联起来,你也能拥有一个只属于你的,能够“看透”世间万物的全能智能体。