
支持 EPUB / MOBI / PDF / DOCX 等 7 种格式,双缓冲无缝播放,完全免费
为什么要造这个轮子?
市面上的 TTS(Text-to-Speech)工具要么收费,要么语音质量差,要么只支持纯文本。我的需求很简单:
- 语音质量要好 — 接近真人朗读
- 支持长文本 — 一本小说几十万字,不能一次性生成
- 支持电子书格式 — EPUB、MOBI 这些主流格式
- 免费 — 不想为听书付月费
于是,EdgeTTSPlayer 诞生了。
技术选型
| 组件 | 选择 | 理由 |
|---|---|---|
| TTS 引擎 | edge-tts | 微软神经网络 TTS,14+ 中文语音,免费无限制 |
| 音频播放 | pygame.mixer | 跨平台 MP3 播放,支持状态检测 |
| GUI 框架 | Tkinter + ttk | Python 内置,零依赖部署 |
| EPUB 解析 | ebooklib | 成熟的 EPUB 读写库 |
| MOBI 解析 | mobi | 解包 MOBI → HTML → 纯文本 |
| PDF 提取 | PyPDF2 | 轻量级 PDF 文本提取 |
| DOCX 解析 | python-docx | Word 文档段落提取 |
最初我用的是 pyttsx3(离线 TTS),但中文语音效果太机械了。切换到 edge-tts 后,差距是质的飞跃 — 它调用的是 Microsoft Edge 浏览器内置的神经网络 TTS 服务,完全免费,语音质量接近真人。
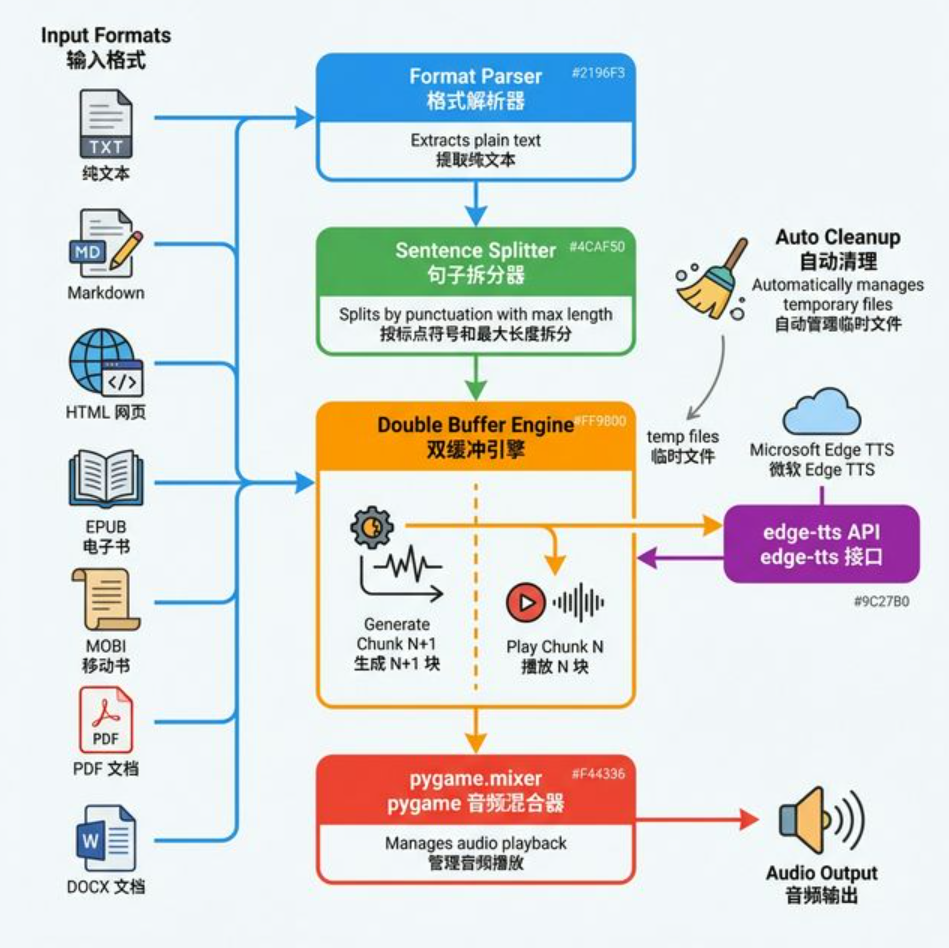
核心架构:断句 + 双缓冲流式播放
长文本直接生成一整段音频,既慢又占内存。我的方案是断句分片 + 双缓冲预加载:
┌──────────────────────────────────────────────┐
│ 文本处理流水线 │
│ │
文件输入 ──→ │ read_book_file() ──→ split_text_to_chunks() │
(7种格式) │ 格式解析 按标点断句 │
└──────────────┬───────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 双缓冲播放引擎 │
│ │
│ ┌─────────────┐ ┌──────────────────┐ │
│ │ 播放 chunk[n]│ │ 生成 chunk[n+1] │ │
│ │ pygame.mixer│◀──▶│ edge-tts + asyncio│ │
│ └──────┬──────┘ └──────────────────┘ │
│ │ 播完后自动删除临时 MP3 │
│ ▼ │
│ 自动切换到 chunk[n+1] │
└──────────────────────────────────────────────┘
1. 智能断句:split_text_to_chunks()
不能简单按固定字数硬切 — 那样会把句子切断,听起来很别扭。我采用了两级断句策略:
# 强分隔符:句号、叹号、问号、分号
SENTENCE_DELIMITERS = re.compile(r'(?<=[。!?;…!?;])|(?<=\n)')
# 弱分隔符:逗号、顿号
CLAUSE_DELIMITERS = re.compile(r'(?<=[,、,])')
算法逻辑:
- 先按强分隔符拆分成句子
- 将句子攒入 buffer,直到接近
max_length(默认 200 字) - 如果单个句子超长,再按弱分隔符(逗号)二次拆分
- 最坏情况下按字数硬切(保证不会死循环)
实际效果(max_length=30):
原文: 今天天气晴朗,万里无云。我出门去散步,走了很长一段路。
到了公园里,看到很多人在锻炼身体!有的跑步,有的打太极拳;
还有些人在唱歌。真是一个美好的早晨。
断句结果:
[1] (27字) 今天天气晴朗,万里无云。我出门去散步,走了很长一段路。
[2] (29字) 到了公园里,看到很多人在锻炼身体!有的跑步,有的打太极拳;
[3] (18字) 还有些人在唱歌。真是一个美好的早晨。
2. 双缓冲播放:边播边生成
这是整个工具的核心设计。如果生成一段、播放一段、再生成下一段,每次切换都会有几秒的空白停顿。
双缓冲方案:
# 播放 chunk[n] 的同时,在另一个线程中预生成 chunk[n+1]
gen_thread = threading.Thread(target=_gen_next, daemon=True)
gen_thread.start()
# 播放当前片段
pygame.mixer.music.load(current_path)
pygame.mixer.music.play()
# 等播放完毕后,下一个片段已经生成好了
while pygame.mixer.music.get_busy():
if self._playback_stop.is_set():
pygame.mixer.music.stop()
return
pygame.time.wait(100)
效果: 片段之间的切换几乎感觉不到停顿,因为下一段音频在上一段播放期间就已生成完毕。
3. 自动清理:不留临时文件
每次播放会在系统临时目录创建一个独立文件夹,每个片段生成为 chunk_0.mp3、chunk_1.mp3 …
- 播放完成的片段立即删除(
pygame.mixer.music.unload()→os.remove()) - 用户点击停止或播放完毕后,整个目录删除(
shutil.rmtree()) - 窗口关闭时也会触发清理
def _cleanup_temp_dir(self):
if self._temp_dir and os.path.isdir(self._temp_dir):
shutil.rmtree(self._temp_dir, ignore_errors=True)
self._temp_dir = None
多格式支持:一个函数搞定
read_book_file() 根据文件扩展名自动选择解析策略:
def read_book_file(file_path):
ext = Path(file_path).suffix.lower()
if ext in ('.txt', '.md'):
return path.read_text(encoding='utf-8')
if ext in ('.html', '.htm'):
soup = BeautifulSoup(html, 'html.parser')
return soup.get_text(separator='\n', strip=True)
if ext == '.epub':
book = epub.read_epub(str(path))
# 遍历所有章节,提取纯文本
...
if ext == '.mobi':
# mobi 解包 → 找到 HTML → BeautifulSoup 提取
...
if ext == '.pdf':
reader = PdfReader(str(path))
# 逐页提取文本
...
if ext == '.docx':
doc = DocxDocument(str(path))
# 提取所有段落
...
MOBI 格式比较特殊 — 它是亚马逊的私有格式,需要先解包到临时目录,找到里面的 HTML 文件,再用 BeautifulSoup 提取文本。解包后的临时目录也会在 finally 块中自动清理。
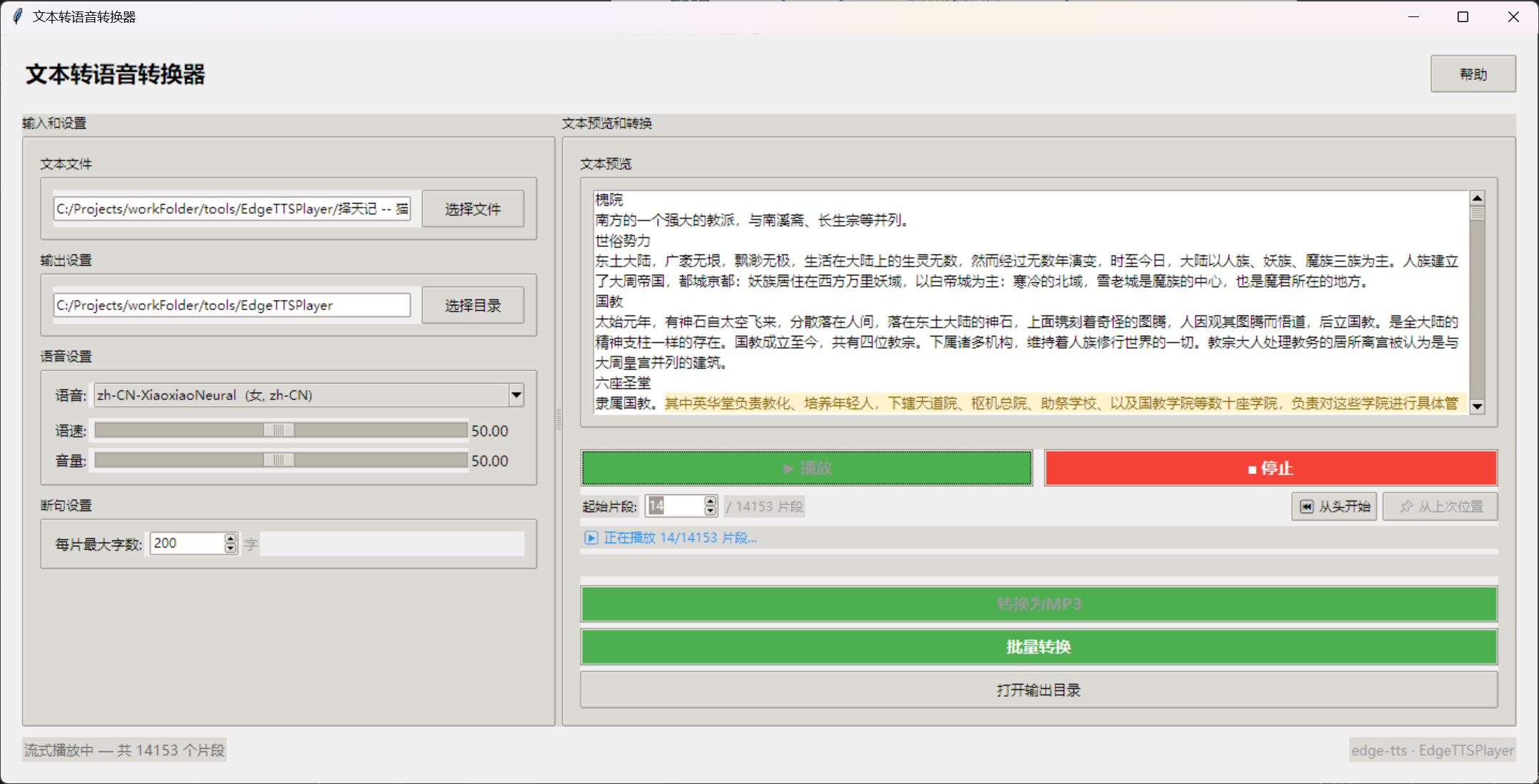
使用效果
运行 python main.py 启动应用后:
- 点击 选择文件 — 支持 TXT/MD/HTML/EPUB/MOBI/PDF/DOCX
- 选择中文语音(14+ 可选)、调整语速和音量
- 点击 ▶ 播放 — 自动断句并流式播放
- 状态栏实时显示
▶ 正在播放 3/142 片段... - 随时点击 ■ 停止,临时文件自动清理
也可以点击 转换为MP3 导出完整音频文件,或 批量转换 一次处理多个文件。
后续路线图 🗺️
当前版本(v1.0)已经可以日常使用,但还有一些有价值的功能计划中:
| 功能 | 描述 | 状态 |
|---|---|---|
| 📖 文本高亮同步 | 播放时自动高亮当前正在朗读的句子 | 计划中 |
| 📌 记忆播放位置 | 关闭后重新打开,从上次停止的地方继续 | 计划中 |
| 🌍 多语言支持 | 扩展到英文、日文等其他语音 | 计划中 |
| 📦 打包为 EXE | 使用 PyInstaller 打包成无需 Python 环境的独立应用 | 计划中 |
快速上手
git clone https://github.com/maifeipin/EdgeTTSPlayer.git
cd EdgeTTSPlayer
pip install -r requirements.txt
python main.py
依赖: Python 3.10+ | 需要网络连接(Microsoft Edge 在线 TTS 服务,免费无限制)
项目地址
🔗 GitHub: maifeipin/EdgeTTSPlayer
欢迎 Star ⭐ 和提 Issue!
作者:maifeipin & Antigravity AI
日期:2026 年 2 月 13 日
技术栈:Python · edge-tts · pygame · Tkinter