1、 部署PandoraNext。
PandoraNext 项目部署非常简单,Readme.MD写得很详细。
PandoraNext在proxy模式下,可以自己管理自己的chatgpt:可以分享给别人,也可以账号密码登录,也可以acess token,session token登录。也可以把这两个token转换成share token,或者打包share token 生成pool token。
由于pool token 是可以一直不变的,所以我们只需更新share token 到 pool token就可以免登录,无限续期了。
2、可以让chatgpt 根据接口文档 生成一个定时从登录到pool token 的python 脚本。结果如下:
import requests
import os
def login_and_save(username, password):
url = "https://yourhost/proxy-api-prefix/api/auth/login"
payload = f'username={username}&password={password}'
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
response = requests.post(url, headers=headers, data=payload)
# 检查响应状态码
if response.status_code == 200:
# 提取access token和session token
access_token = response.json().get('access_token', '')
session_token = response.json().get('session_token', '')
# 返回access token、session token和整个响应结果
return {'username': username, 'access_token': access_token, 'session_token': session_token, 'response': response.json()}
else:
# 打印错误信息
print(f"请求失败,状态码: {response.status_code}, 错误信息: {response.text}")
return None
responses = []
with open('account.txt', 'r') as account_file:
for line in account_file:
# 分割用户名和密码
username, password = line.strip().split('|')
# 调用登录函数获取access token、session token和响应文本
login_result = login_and_save(username, password)
# 如果成功获取access token,则将结果保存到列表中
if login_result:
responses.append(login_result)
for response in responses:
username = response['username']
access_token = response['access_token']
session_token = response['session_token']
# 在这里添加后续的处理逻辑,使用access token和session token
# ...
# 例:使用access token和session token访问另一个API
second_url = "https://yourhost/proxy-api-prefix/api/token/register"
# 构建第二次请求的payload
second_payload = f'unique_name=fakeopen&access_token={access_token}&site_limit=&expires_in=0&show_conversations=true&show_userinfo=true'
second_headers = {'Content-Type': 'application/x-www-form-urlencoded'}
# 发送第二次请求
second_response = requests.post(second_url, headers=second_headers, data=second_payload)
# 构建输出文件名,以用户名.txt形式
output_filename = f'{username}_second_request.txt'
# 删除原文件(如果存在)
if os.path.exists(output_filename):
os.remove(output_filename)
print(f"已删除原文件: {output_filename}")
# 将第二次请求的响应结果写入文件
with open(output_filename, 'w') as output_file:
output_file.write(second_response.text)
print(f"第二次请求成功,结果保存到文件: {output_filename}")
...
3、部署ChatGPT-Next-Web
a、可以直用项目地址的方式安装,然后需要手动在客户端的设置里使用自定义接口,填入PandoraNext的地址/proxy-api-prefix 和pool key 。
b、把项目fork后修改base-url或下载后本地部署,在服务端嵌入配置,客户端可以直接使用。
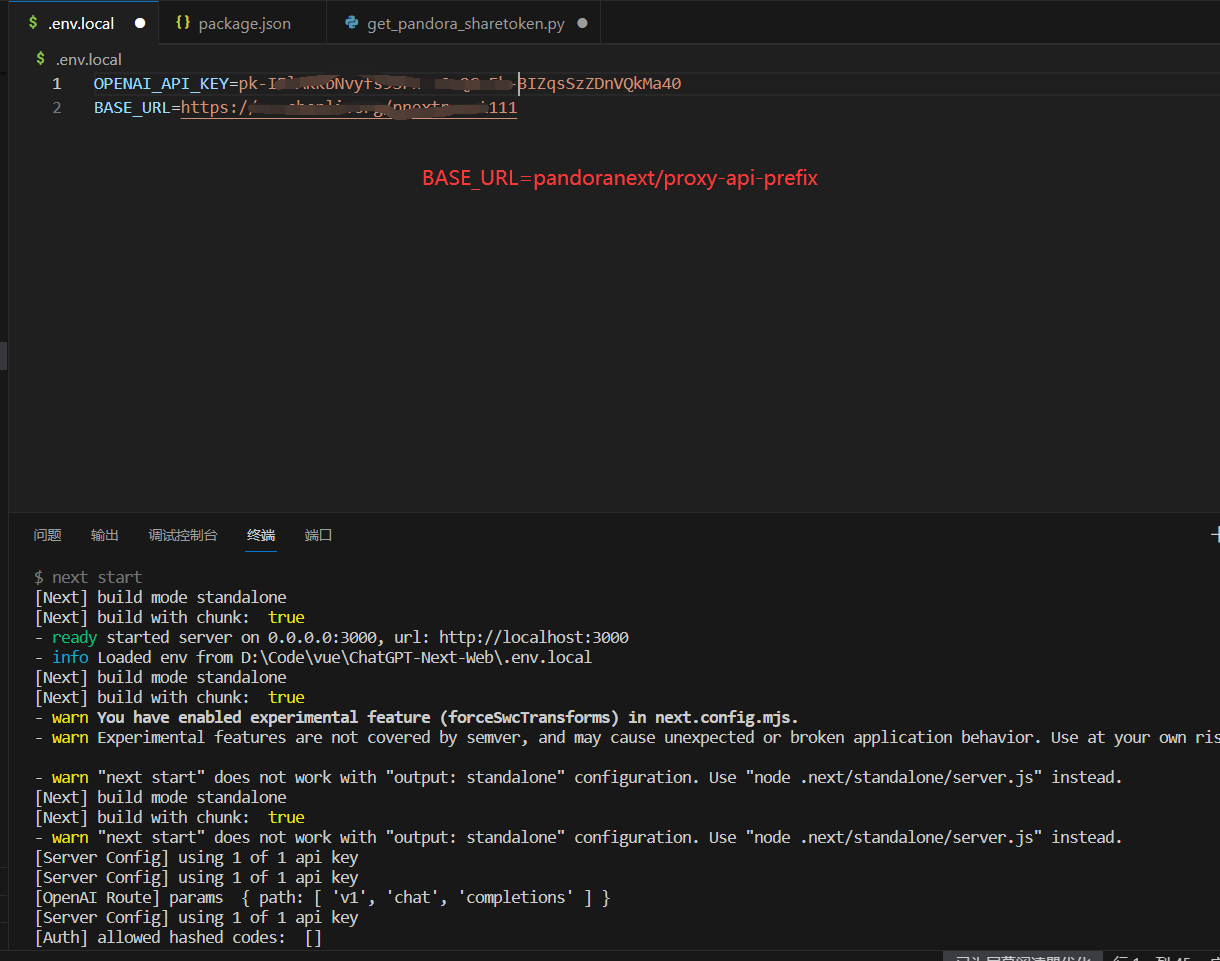
git clone 项目.git 到本地,在根目录添加 .env.local 文件。填入 OPENAPI Key 和 BASEURL,再用nvm 安装 并切换到 node 18版本。执行 yarn install && yarn build && yarn start 。
.env.local
如果服务器上,可以用pm2做进程维护。
nano ecosystem.config.js
module.exports = {
apps: [
{
name: 'catgpt-net-web',
script: 'yarn',
args: 'start',
cwd: '/path/to/yourchatgptnextweb', #这个改为你的chatgptnexweb的路径
instances: 1,
autorestart: true,
watch: false,
max_memory_restart: '1G',
log_date_format: 'YYYY-MM-DD HH:mm Z',
env: {
NODE_ENV: 'development'
},
env_production: {
NODE_ENV: 'production'
}
}
]
};
通过PM2启动: pm2 start ecosystem.config.js --env production

最后,到这里就可以使用了,如果有需求不想暴露端口又有域名,给个二级域名反代出来。就可以愉快的玩耍了。