Craw4ai 是一个免费开源的 网页提取工具,官方文档 🚀🤖 Crawl4AI: Open-Source LLM-Friendly Web Crawler & Scraper
安装
-
用pip安装需要独立的虚拟环境。否则报错
root@localhost:~# pip install crawl4ai error: externally-managed-environment × This environment is externally managed ╰─> To install Python packages system-wide, try apt install python3-xyz, where xyz is the package you are trying to install. If you wish to install a non-Debian-packaged Python package, create a virtual environment using python3 -m venv path/to/venv. Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make sure you have python3-full installed. If you wish to install a non-Debian packaged Python application, it may be easiest to use pipx install xyz, which will manage a virtual environment for you. Make sure you have pipx installed. See /usr/share/doc/python3.12/README.venv for more information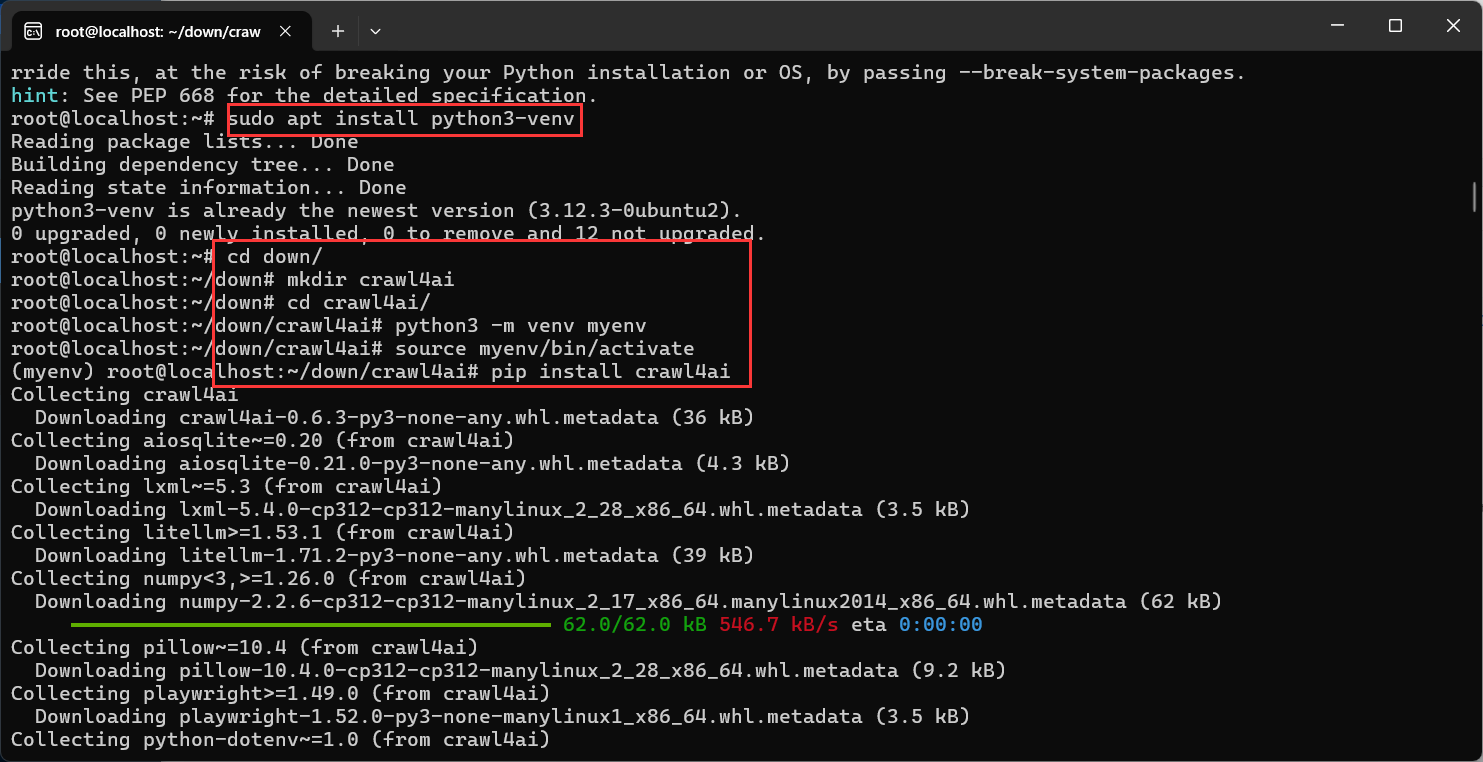
可以看出这个依赖有点多
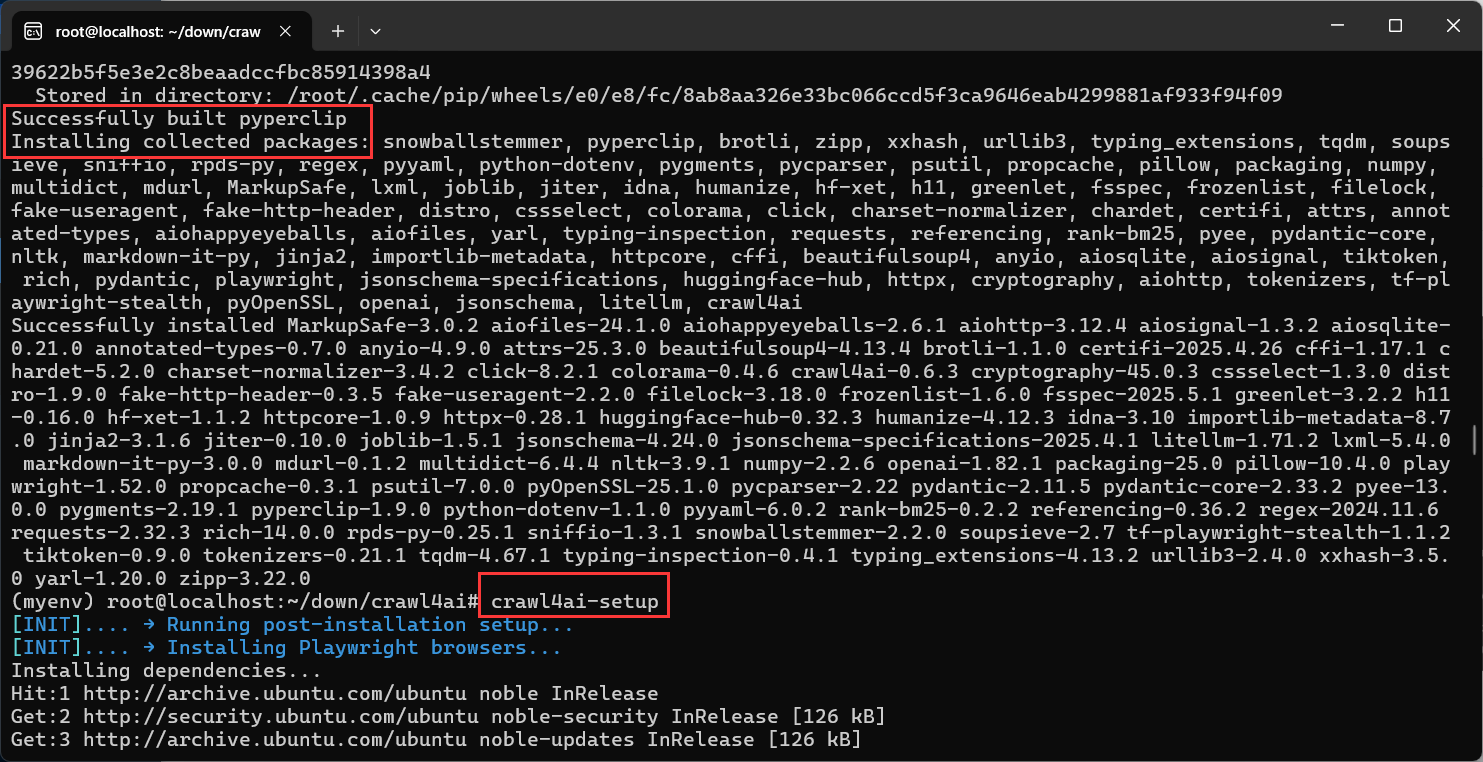
-
验证安装
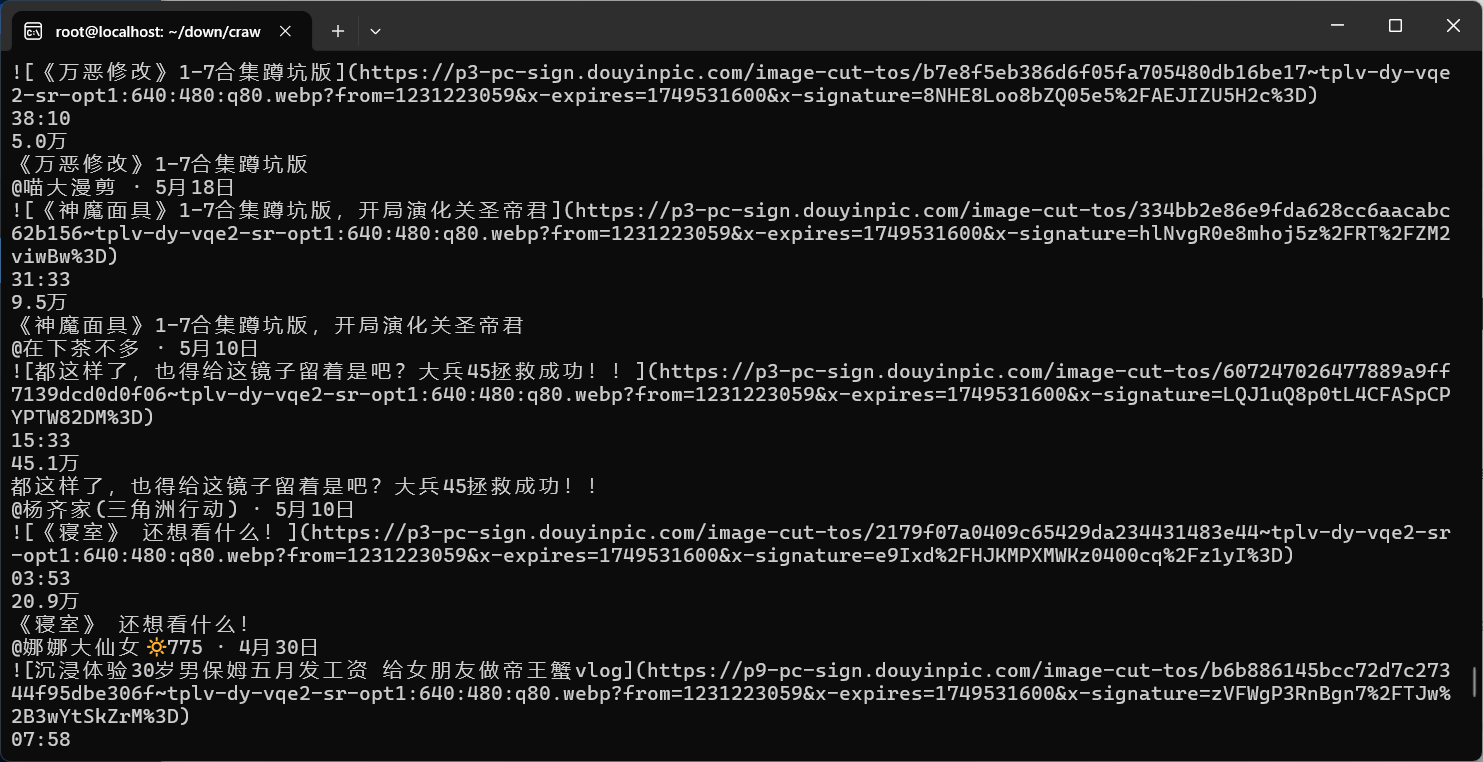
抓取抖音的代码import asyncio from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig async def main(): async with AsyncWebCrawler() as crawler: result = await crawler.arun( url="https://www.douyin.com/jingxuan", ) print(result.markdown) # Show the first 300 characters of extracted text if __name__ == "__main__": asyncio.run(main()) -
获取数据