
💡 引言与痛点
你手里有几张信用卡?
招行、工行、浦发、民生、中信、华夏……每家银行的账单日不同、还款日不同,甚至连账单发送的格式也千差万别。
- 有的银行邮件里是密密麻麻的 HTML 表格;
- 有的银行是纯文本;
- 更有甚者,外币账单和本币账单混杂,对账全靠肉眼和计算器。
为了彻底终结“手动翻邮件、人工算对账”的痛苦,我决定用 Python 撸一个信用卡账单自动解析、记账与对账工具。
在架构设计上,我给自己提了一个近乎苛刻的要求:零外部依赖(0 Third-Party Dependencies)。整个项目只使用 Python 内置的标准库,不调任何 requests、pandas 或 tabulate 等第三方包。
这样做不仅让程序极其轻量、开箱即用,更在当今 人机协同(Human-Agent Co-working) 的时代下,创造了一个对 AI 编码助手(如 MCP、Skill)极其友好的“极简核心”。
今天,就把这个项目的技术架构和开发中踩过的“巨坑”分享给大家。
✨ 项目核心功能一览
项目基于 邮件拉取 (POP3) -> 规则匹配模板 -> 提取核心字段 -> 解析交易明细 -> SQLite 持久化 -> 智能报表与对账 的完整闭环搭建。
通过双击根目录下的启动脚本,即可开启一个高颜值的终端交互控制台:
1. 🔌 邮箱多协议连通性一键测试
支持测试 POP3(收信)、IMAP(同步)和 SMTP(发信)等协议的连通性与授权状态,提供开箱即用的环境检测。
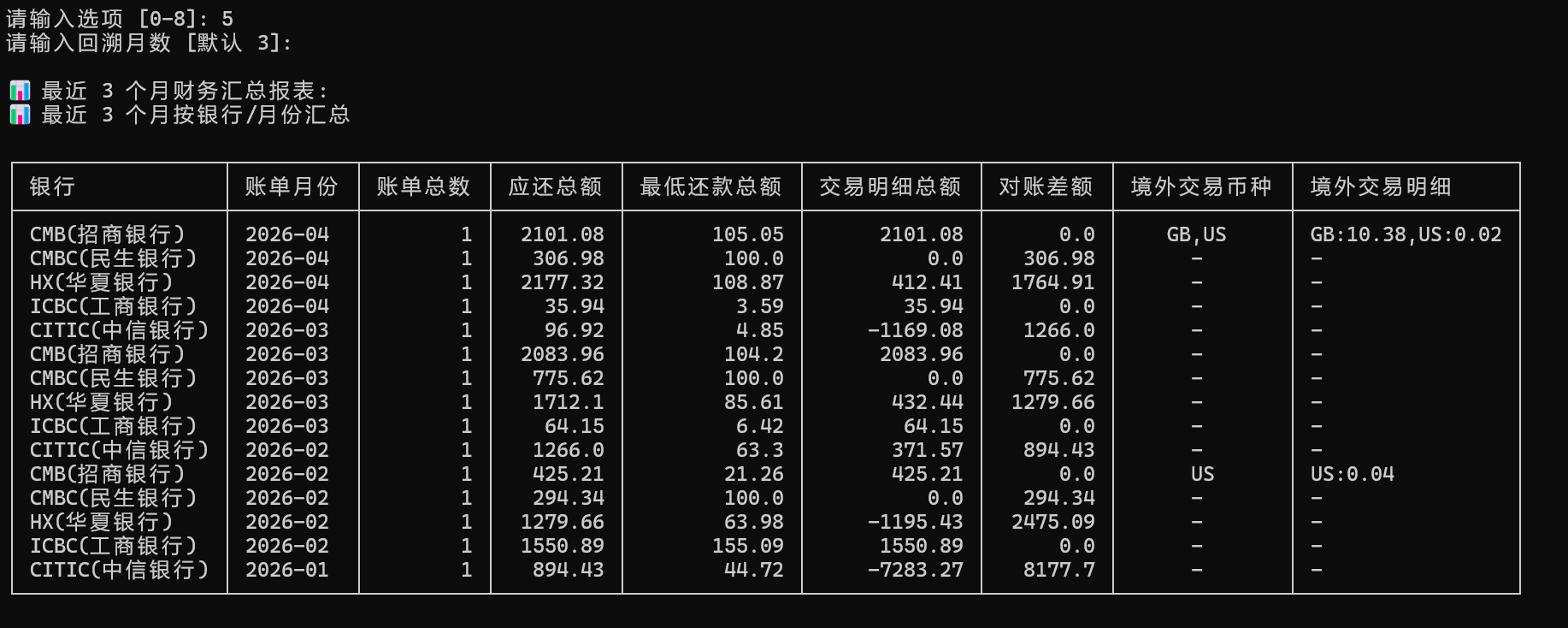
2. 📊 银行 / 月度财务汇总报表(含境外交易)
自适应列宽的 Unicode 框线报表,直观汇总各银行的账单状况。特别支持境外消费原币种与金额的提取与细分汇总。
3. 🧾 智能自动对账系统 (Reconcile)
程序能够自动提取邮件中的账单主表总额(total_due),并与自动解析出的几十笔交易明细单笔累加值进行比对。一旦差额超出容差范围(如 元),立即输出 ❌ CHECK 状态提醒人工排查,对账通过则显示 ✅ PASS。
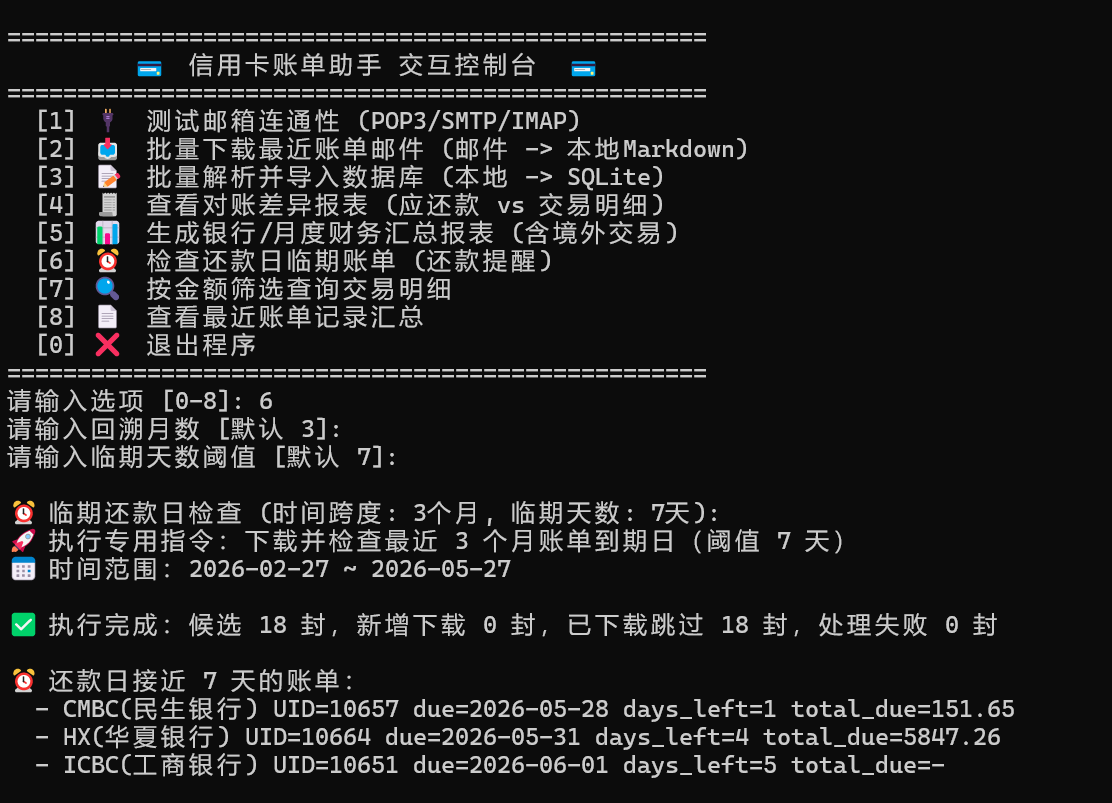
4. ⏰ 还款日临期预警与提醒
自动回溯多银行账单,提取还款日期,精准计算并展示未来 天内即将到期的信用卡,告警逾期风险。
🛠️ 核心架构与设计
整个项目由三个核心模块构成,各司其职:
mail_client.py:主入口。负责邮件拉取、HTML 转换为 Markdown、调用解析引擎与命令行 UI。statement_db.py:SQLite 持久化层。负责账单主记录、交易明细的落库,以及复杂的汇总、对账 SQL 查询。statement_models.py:领域模型定义。定义账单实体、校验错误等。
核心解析引擎:基于 JSON 模板的匹配与提取
为了支持多银行,我设计了基于 JSON 配置的解析引擎。新增一家银行,完全不需要修改 Python 源代码,只需在 rules/ 目录下放置一个对应的 JSON 规则文件即可。
以下是招商银行账单配置文件的缩影:
{
"schema_version": "1.0",
"rule_id": "CMB_TEMPLATE_V1",
"bank_code": "CMB",
"match_rules": {
"sender_patterns": ["message@cmbchina.com"],
"subject_patterns": ["招商银行信用卡电子账单"]
},
"extract_rules": {
"statement_fields": {
"total_due": {
"type": "regex",
"source": "body_text",
"pattern": "本期应还款总额[::]?\\s*([+-]?[0-9,]+\\.[0-9]{2})"
},
"due_date": {
"type": "regex",
"source": "body_text",
"pattern": "到期还款日[::]?\\s*(20\\d{2}[-/]\\d{1,2}[-/]\\d{1,2})"
}
}
}
}
匹配引擎会给所有规则打分(发件人、主题、正文特征码权重叠加),自动挑选出最契合 the 模板进行正则提取,极具扩展性。
🔥 技术攻坚与细节分享
在坚持零外部依赖的原则下,我遇到了两个极其棘手的技术挑战,并给出了非常优雅的解决方案:
挑战一:终端表格中英文混排的“东亚字符对齐”难题
在终端打印表格时,如果内容包含中文,你会发现表格框线全部错位了。这是因为标准的 len() 函数计算的是字符个数,而中文字符在终端显示时占用的宽度是英文字符的 2 倍。
💡 优雅解法:自适应 CJK 字符宽度计算器
我通过 Unicode 字符集编码范围,实现了一个能够精准计算中英文混排字符串实际显示占位宽度的函数:
def get_display_width(s):
if s is None:
return 0
s = str(s)
width = 0
for char in s:
o = ord(char)
# 判定是否属于中日韩(CJK)统一汉字、全角符号、韩文字母等宽字符区间
if (0x1100 <= o <= 0x115F or
0x2E80 <= o <= 0x303F or
0x3040 <= o <= 0x309F or
0x30A0 <= o <= 0x30FF or
0x3100 <= o <= 0x312F or
0x3130 <= o <= 0x318F or
0x3190 <= o <= 0x319F or
0x31A0 <= o <= 0x31BF or
0x31C0 <= o <= 0x31EF or
0x31F0 <= o <= 0x31FF or
0x3200 <= o <= 0x32FF or
0x3300 <= o <= 0x33FF or
0x3400 <= o <= 0x4DBF or
0x4E00 <= o <= 0x9FFF or
0xF900 <= o <= 0xFAFF or
0xFE30 <= o <= 0xFE4F or
0xFF00 <= o <= 0xFFEF):
width += 2
else:
width += 1
return width
在此基础上,重写了字符串填充逻辑 pad_string:
def pad_string(s, width, alignment='left'):
s = str(s) if s is not None else ''
cur_width = get_display_width(s)
padding = width - cur_width
if padding <= 0:
return s
if alignment == 'right':
return ' ' * padding + s
elif alignment == 'center':
left = padding // 2
right = padding - left
return ' ' * left + s + ' ' * right
else:
return s + ' ' * padding
这使得表格在面对 CMB(招商银行)、ICBC(工商银行) 等中英混排字符串时,依然能实现像素级的完美框线对齐!
挑战二:Windows CMD 默认 GBK 编码与 Emoji 打印崩溃
Windows 系统终端(cmd.exe)的默认代码页是 GBK (936)。当 Python 程序试图打印含有 📄、🔌、✅、❌ 等万国码 Emoji 或者复杂的 UTF-8 字符时,程序会直接抛出著名的 UnicodeEncodeError: 'gbk' codec can't encode character... 崩溃退出。
更坑的是,如果试图用 UTF-8 编写 .bat 启动脚本,Windows CMD 在还没执行第一行 chcp 65001 之前,就会用 GBK 去解码批处理文件,直接导致“乱码报错,无法识别命令”。
💡 优雅解法:“纯 ASCII 引导 + 标准流劫持”
为了完美解决这个巨坑,我采取了两步走策略:
- 写一个 100% 纯 ASCII 的 run.bat:
批处理文件内部绝不出现任何中文字符(全部用 ASCII 英文字符),这样无论在什么国家、什么代码页的 Windows 下,CMD 都能顺利解析启动它。
启动后的第一行,再静默执行切换代码页:@echo off chcp 65001 > nul python "%~dp0mail_client.py" menu - 在 Python 代码入口强制劫持标准流为 UTF-8:
在mail_client.py头部加上平台判断,如果是 Windows,直接用TextIOWrapper劫持sys.stdout和sys.stderr为utf-8:if sys.platform.startswith('win'): import io sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8') sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8')
这一套组合拳打下来,不管用户本地终端默认是什么编码,双击运行一秒切换 UTF-8,中文字符和 Emoji 渲染如丝般顺滑!
🔮 总结与未来展望:迈向“人机协同”时代
这个项目目前已经满足了我对信用卡账单管理的一切幻想:它足够轻(0依赖),足够快(SQLite本地),足够智能(多行对账校验),同时颜值拉满。
更重要的是,它完美的契合了未来的 Agent 友好型设计模式。
在 AI 编码助手大行其道的今天,臃肿的 GUI 界面或过多的外部依赖包不仅减慢了运行速度,还把逻辑变成了黑盒。保持 CLI 命令输出标准化 + SQLite 本地关系型存储,可以让如 Cline、Antigravity 这样的 AI Agent 以极高精度理解你的数据库和调用你的 CLI。
未来,我计划为这个项目延伸一个**“轻量 Web 看板”**,依然保持核心 CLI 与数据的纯净,而由 Python 本地拉起一个华丽的现代 HTML5 可视化大屏。
- 本项目完整开源,欢迎大家在自己的本地尝试部署运行!